

[links] Stop Making Sense
Generative AI decoding your visual neurodata / Slime Mold Tamagotchi Watch / Stable Diffusion trained on Cats - The Movie.

Stop Making Sense in Latent Space Photography
I absolutely love the AI-photography of Roope Rainisto who trained a Stable Diffusion-model with Dreambooth on supposedly surrealist landscape and architecture. These images/ai-photographies/latent-space-explorations are otherworldly and dreamlike, they show a weird, labyrinthic quality to them that is unique to ai-generated art.
I more and more come to believe that the artwork produced in generative ai is in the models themselves, and we are the mere explorers of that artwork, curating what we see. Like i said a few weeks ago:
Here’re the image series on Twitter: Lost In Translation, Songs of Wander, Stop Making Sense, Life Simulation, The Social Experiment, Tourism Destination, Life In A Society Of Ideals, Connected Culture, Big Screen, Tourist Visa, Infinite Road. I recommend all of them, but Postmodern Labor and Get Me To Flavor Town really takes the cake.Some favs below:



Images reproduced from visual brain data
In MinD-Vis, researchers present another technique to for decoding images from brain data with AI. After a paper from MetaAI about non-invasive language decoding, a preprint on bioxiv about the semantic reconstruction of continuous language from non-invasive brain recordings, a GAN that reproduces faces seen by a monkey and a BCI for image editing, it seems to me that the BCI-to-AI-Pipeline is speeding up. Though the results in this paper are only somewhat accurate as of now, given the speed of improvements this year this could go very fast.

So it’s time to get serious about the impact of BCI/AI on Neuroprivacy, not to speak of the psychological effects of technology that can read your thoughts and generate plausible output, maybe even without you noticing. Just as hackers can 3Dscan a room with WiFi signals, this technique may be used to infer neural data (from blood pressure? Heat?). Also, very soon, AI systems may be trained directly from neural data to produce mimetic AI-models which can act to optional extends on behalf of the owner of that data.
In a recent post i wrote about the very possibility of a BCI/AI-technology consisting of a headset which can read our thoughts and directly visualize what we think in a virtual world. I called this tech a form of digital lucid dreaming, and if you can hack such a device and directly access it, you can not only read minds, you actually would be able to malkovichmalkovichmalkovich into my brain like John Cusack in Spike Jonzes excellent masterpiece Being John Malkovich.
These outlooks are awesomely frightening and the questions arising from these very real possibilities are anything but adressed.
MinD-Vis-Paper: https://arxiv.org/abs/2211.06956, from their project page:
Decoding visual stimuli from brain recordings aims to deepen our understanding of the human visual system and build a solid foundation for bridging human vision and computer vision through the Brain-Computer Interface. However, due to the scarcity of data annotations and the complexity of underlying brain information, it is challenging to decode images with faithful details and meaningful semantics.
In this work, we present MinD-Vis: Sparse Masked Brain Modeling with Double-Conditioned Diffusion Model for Vision Decoding. Specifically, by boosting the information capacity of representations learned in a large-scale resting-state fMRI dataset, we show that our MinD-Vis framework reconstructed highly plausible images with semantically matching details from brain recordings with very few training pairs. We benchmarked our model and our method outperformed state-of-the-arts in both semantic mapping (100-way semantic classification) and generation quality (FID) by 66% and 41%, respectively. Exhaustive ablation studies are conducted to analyze our framework.
Highlights
- A human visual decoding system that only reply on limited annotations.
- State-of-the-art 100-way top-1 classification accuracy on GOD dataset: 23.9%, outperforming the previous best by 66%.
- State-of-the-art generation quality (FID) on GOD dataset: 1.67, outperforming the previous best by 41%.
- For the first time, we show that non-invasive brain recordings can be used to decode images with similar performance as invasive measures.
Infinite Nature: Generating 3D Flythroughs from Still Photos: “In a research effort we call Infinite Nature, we show that computers can learn to generate such rich 3D experiences simply by viewing nature videos and photographs. Our latest work on this theme, InfiniteNature-Zero (…) can produce high-resolution, high-quality flythroughs starting from a single seed image, using a system trained only on still photographs, a breakthrough capability not seen before.”
DeviantArt upsets artists with its new AI art generator, DreamUp
DeviantArt made their own image generator and a license model where illustrators and artists can opt in for dataset use. No words on compensation like Shutterstock (yet) and I guess this will be the default for image sharing platforms for artists, who can, if they wish to, take part in AI training.
This, ofcourse, will only create a black market (which is already flourishing) with all kinds of dreambooths for all kinds of styles, artists and genres. You want Product Photography for Cars in the style of Annie Leibovitz? There's a CKPT for that. (A CKPT is the file-format for generative ai-diffusion-models.)
Its the same situation with Filesharing after the fall of Napster, and until there is a Spotify for artistic styles, people will train their own AI-models on images floating on the internet and generate millions of pics in the style of any artist, alive and dead, opt in or out be damned.Weird visitations from uncanny valley: This man has combined his impressionist skills with deepfake video editing and its way past creepy.
"Seraphim: A Biblically-Inspired Constructed Language", Babelingua ("for multiple mouth angels using gematria to define phonemes, speaking in syntax trees + singing multilingual 4D-tense praises")
With the flood of AI generated images the new thing seems to be AI art contests. One of the better results comes from Claire Silver, all the pieces in this thread are great.
“I trained my tiktok algorithm to show videos that are so surreal you feel like you’re dreaming. here’s a thread of my favorites.”
Guillermo Del Toro Releases AT THE MOUNTAINS OF MADNESS Test Footage. I will not cease hope, iä iä fhtang.
Baking Icelandic rúgbrauð bread in a San Fernando Valley heatwave.
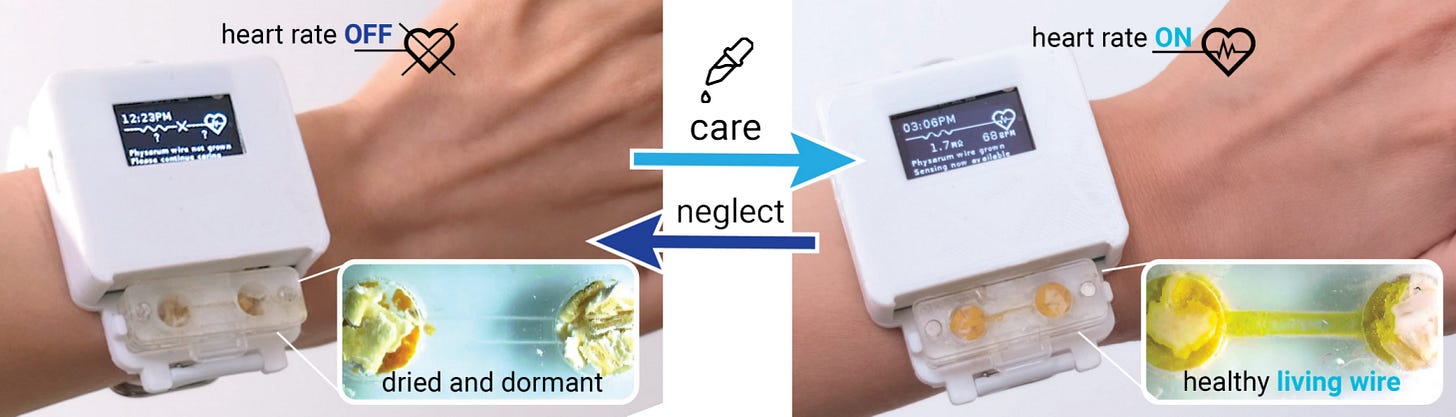
Behold the Slime Mold Tamagotchi Watch: “The watch displayed the time and was capable of measuring your heart rate, but only if the slime mold is healthy. In short, if you want to get full functionality out of the watch, you need to feed it, water it, and make sure it’s happy, not unlike the Tamagotchis we grew up with.”
a timeline of Ten Years of Image Synthesis
a visual history of artificial neural networks from 1943 to 2020
An explorable map of KREA AI's Stable Diffusion Search Engine
Cool Stable Diffusion dreambooth-models: Van-Gogh-diffusion / D&D model trained for 30,000 steps on 2500 manually labelled images / JWST-Deep-Space-diffusion / and the almighty Cats-Musical-diffusion. (I’m thinking about training a dreambooth on all the Classic Universal Monsters, stills from those movies, close ups and Posters. Someone has to do this, but sadly, my resources are… subpar for the job atm. If somebody wants to give this a shot, go for it.) Anyways, here’s everybody in Cats:


