

The Skeleton Library
On Interpolatable Archives, Part 1: Compulsions to Connect, Warburg, Borges and Goldsmith, Cultural Technologies and Digital Oralities
I’ve been throwing around the term “Interpolatable Archives” for quite some time when talking about Language Models and Artificial Intelligence, and I finally got around to write down what I mean by that. It got a bit out of hand, and I had to split up this essay into four parts, all of which will be published in the coming days.
Here’s an overview of what’s to come:
Part 1: The Skeleton Library - Compulsions to Connect, Warburg, Borges and Goldsmith, Cultural Technologies and Digital Oralities
Part 2: Explosion Drawings - Science Sans Discoveries, Textrotating Cognitive Catalysts and Exploding Your Intelligence by the Method of Warburg
Part 3: Pitfalls of Probability - Accelerations, Anachronisms, Wishfulfillments, Severances and Homogenizations
Part 4: Critical Vibes - Useless Bullshit, Sloptimizations, Vacuum Critiques and Leftovers
“I am unpacking my library. Yes, I am.
The books are not yet on the shelves,
not yet touched by the mild boredom of order.”
(Walter Benjamin)
Compulsions to Connect
One hundred years ago, a german scholar named Aby Warburg went mad over what he called his “Verknüpfungszwang”, a compulsion to connect. He was searching for instances of what he called “Pathosformel“, aesthetic commonalities in the expressions of human emotional states — joy and rage, grief or ecstasy — through cultural history.
To achieve his goal, he built the initial Warburg Institute1 in Hamburg where he collected art, books, news snippets and artifacts. For his opus magnum of the Mnemosyne Atlas (”Bilderatlas Mnemosyne“ in german), he displayed a collection of 971 artifacts on 63 large panels, each two meters high, and indexed them not by the usual meta data like genre, author, date, or topic, but by idiosynratic aesthetic categories and psychological, affective intensity. Here’s some of the labels by which he sorted this collection: “Different degrees in the application of the cosmic system to mankind”, “Orientalizing of antique images”, “Development from Greek cosmology to Arab practice”, “Rimini pneumatic conception of the spheres as opposed to the fetishistic conception” or “Cosmology in Dürer”.

With the Mnemosyne Atlas, an associative image-based map of meaning, Warburg aimed at what he called an “iconology of intervals”, where meaning through analysis of images doesn’t emerge from historic context, but from the space inbetween associated but otherwise unrelated, anachronistic images. His associative Bilderatlas can be read as an early prototype of the latent space of an image model, whichs output was the “Pathosformel”, averaged primitives of affect expressed across cultural history. 100 years later this kind of navigation of an idea space would be newly theorized in context of machine learning by Peli Grietzer in his Theory of Vibes, which, to him, are cognitive maps allowing us to interpret experiences through lossy compression of holistic patterns.
Aby Warburgs’ project of the Mnemosyne Atlas remained unfinished, he died in 1929 from a heart attack. Today, his archive resides in the Warburg Institute in London.
12 years after Warburgs’ death, Jorge Luis Borges published a collection of shortstories called ”The Garden of forking Paths”. It contains at least two stories of interest to our cause, about at least one of which you surely must have heard: ”The Library of Babel” consists of books of 410 pages, containing all possible combinations of 22 letters2 plus period, comma, and spacing. That fictional library includes the random and nonsensical aswell as the meaningful, it holds “the detailed history of the future, the autobiographies of the archangels, the faithful catalogue of the Library, thousands and thousands of false catalogues, the proof of the falsity of those false catalogues, the proof of the falsity of the true catalogue, the gnostic gospel of Basilides, the commentary upon that gospel, the commentary on the commentary on that gospel, the true story of your death, the translation of every book into every language”. It contains a book telling the exact story of your life, and another one that tells mine, and all the books making fools out of both of us.
Analyzing the stories of Borges in context of Large Language Models, in their paper “Borges and AI“, Léon Bottou and Bernhard Schölkopf write about the epistemological unrooting inherent to an archive of such nature: “The books in this Library bear no names. All that is known about a book must come from maybe another book contradicted by countless other books. The same can be said about the language model output. The perfect language model lets us navigate the infinite collection of plausible texts by simply typing their first words, but nothing tells the true from the false, the helpful from the misleading, the right from the wrong.” The only thing relevant for the LLM is not truth, but the narrative consistency of its vector.
In his initial essay on ”The Total Library”, the nonfictional forerunner to “The Library of Babel“, Borges aknowledges its roots in Kurd Laßwitz‘ shortstory “The Universal Library“ (”Die Universalbibliothek” in german) from 1904, likely the first piece of fiction taking the infinite monkey theorem to its logical conclusions. In it, Laßwitz not only predicts the near infinite latent spaces of AI like Borges, but also the pervasive threats of hallucinations, distortions in history writing, deepfakes (here, of documents signed with your name), and humans rendered unable to grasp the endless possibilities of an infinite library, because human reality is bound to practice constrained by real life in a civil society. These are precisely the questions we are confronted with today, anticipated 120 years ago by Kurd Laßwitz, 100 years ago by Warburg, and 80 years ago by Borges.
In 2002, New York based poet Kenneth Goldsmith started to retype his library on a Royal Classic Typewriter, word by word. Later, he was annoyed by the limits of his own taste and incorporated other works to retype, as he calls it, “the platonean ideal of a library”.

As an artist, Goldsmith is explicitly interested in the mundane, the unoriginal, the average, the uncreative -- proudly he declares “I am the most boring writer that has ever lived”3. and says “If I’m doing a piece of writing, and ask myself, can this in some way be construed as not being writing, then I know I’m on the right road.” Because everything ever has already been said in all possible combinations, adding to the cultural output to him feels pointless, so he runs with that feeling and turns futility in the face of borgesian infinities into its own poetic form.
Goldsmith sometimes thinks of himself as a modern version of Borges’ “Pierre Menard, Author of the Quixote“ from the shortstory of the same name, but he concedes that fictional Menard is more original. In this story, Menard wants to hyper-translate Cervantes “The Ingenious Gentleman Don Quixote of La Mancha” by immersing himself so deeply into work and life of its author he’ll become able to re-create it, line by line, without copying. In AI-parlor, Menard aims to overfit himself on Cervante so hard that his writing will be able to put out the original text.
With breaks, Goldsmith is retyping a library for 24 years now, and to date, he copied 750 books on ultra-thin onion-skin paper, which he stores in 200 boxes. Each book comes with a self-drawn portrait of the original author and her signature. Goldsmiths project is creating a singularity within the infinite floods of content production, to link unique individual and averaged mass.
What all of these authors across the ages have in common is Warburgs’ “compulsion to connect” archival contents, to find meaning in gargantuan amounts of data, each in their own ways.
Today, Warburgs’ Verknüpfungszwang is the prime human condition. Hypertext and platforms connect everything with everyone into what we call “big data”; the former 6 degrees of seperation have shrunk to 4. In consequence, we developed psychological pathologies showing up in widely spread conspirational thinking and delusions big and small, and the political parasites feeding on them.
While Goldsmith was copying lines from the classics on his typewriter, AI labs automatized Warburgs’ Verknüpfungszwang, and OpenAI released a new transformers based language model.
ChatGPT went public.
The Skeleton Library
Imagine a library devoid of letters. All the books it once contained are dissolved, its contents gone. What survives are the bookbindings, the cartonage, blank pages, the shelves, sections and all the floors of said library. The buildings stay intact, all the catalogs are there.
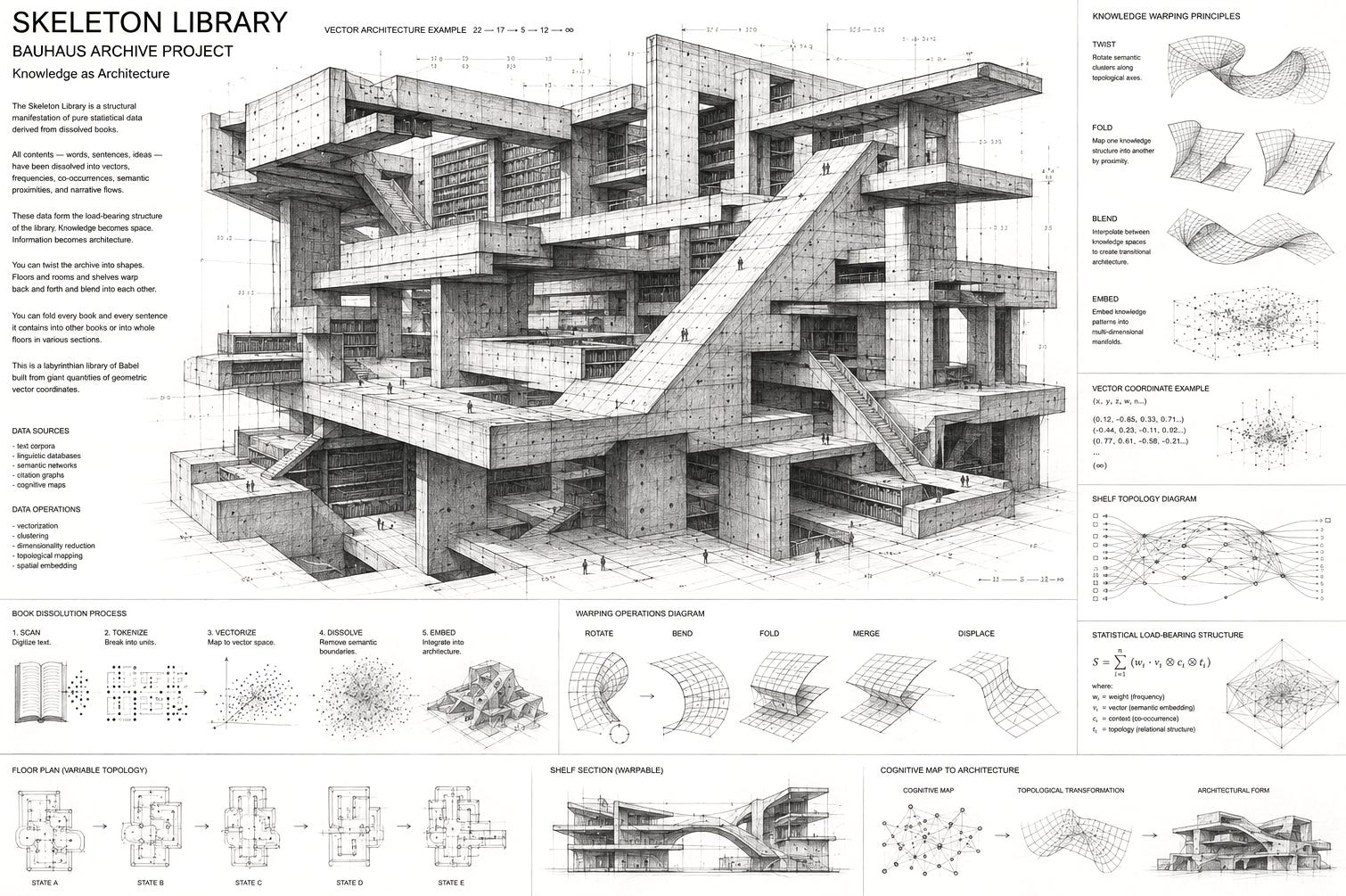
Some machine, at one point, went through this library, scanned all the letters within those books, noted all the statistics it could possibly measure on its path: the exact position of each letter in each book, the locations of those books in their shelves, the exact size in width, height and depth of all books, shelves, floors, their angles and distances to each other, a precise floor plan of the library, and how all this spatial information relates to each book, sentence, and character. On scanning the pages, the typography vanishes, leaving only blank sheets of paper. This is a library of pure structure, where Peli Grietzers “cognitive map” has been turned into architecture, the remainder skeleton of an archive built from giant quantities of geometric vector coordinates so finegrained that you can derive any information about its former collection.
Now imagine that you can fold this skeleton library, twist it into shapes not possible before. Like in a drawing by M.C. Escher, the floors and rooms and shelves bend back and forth and blend into each other. You can fold every book and every sentence it contains into other books or into whole floors in various sections. Imagine warping the cookbook shelf into the section for crime fiction, or blending the songbooks of punk rock bands from the 70s with the floor of classic literature. You can give it a spin and delegate the resulting amalgam to the building containing textbooks of natural sciences, letting it articulate all of this in the language of mathematical formulas. This is prompting: Morphing and twisting the skeleton of an archive consisting of extremely detailed statistics about the properties of its former contents, ready to be blended and remixed with any other data-point within that embedding space.
Another way to understand this skeleton library is by shining a light through it: Imagine your thoughts and ideas as a beam of light shot through a shapeshifting prism, which you can bend into any form and split your mental lightbeam into all colors from all directions in all angles. That prism4 is made from patterns in collective knowledge, and you can explode your own ideas by sending them through those prisms, where the output is a refracted thought dispersed into the components of whatever was your idea, and you can look at it from many perspectives.
This explosion drawing of your thought is comparable to Douglas Hofstaedters Trip-Let, which he describes in “Gödel, Escher, Bach“ as “Blocks shaped in such a way that their shadows in three orthogonal directions are three different letters.” In our analogy for AI, depending on the direction of the lightbeam that is your idea and the location in latent space you aim at with a prompt, the interpolatable archive will throw back very different shadows. Except the “three orthogonal directions” of the Trip-Let have been blown up to hundreds of billions of parameters.
This is the interpolatable archive, a new way to access information mediated through the form of statistics. This is, in my view, the central innovation we can observe in Large Language Models, and possibly machine learning as a whole.
Cultural Technologies, not agents
In their 2025 paper, Alison Gopnik, Henry Farrell and Cosma Shalizi describe Large Language Models as systems which “do not merely summarize (…) information, like library catalogs, Internet search, and Wikipedia” but “also can reorganize and reconstruct representations or ‘simulations’ of this information at scale and in novel ways, like markets, states and bureaucracies”. As multiple studies have shown, LLMs in fact are compressions of their training data5, they are, in fact, Ted Chiangs’ famous “blurry JPGs of the web”, just like “market prices are lossy representations of the underlying allocations and uses of resources, and government statistics and bureaucratic categories imperfectly represent(ing) the characteristics of underlying populations”.
Neither markets nor bureaucracies nor the internet nor language models are agents, they are not cognite, and they are not remotely conscious. But we do like to anthropomorphize all of them anyways: Markets make use of “inivisible hands” and they “react”; we represent the bureaucratic management of nations in the shape of mascots and mythic heroes to bind its people to a narrative; and we talk to language models as if they are buddies, assistants, companions, romantic partners or slaves. The human predisposition to see peoples’ faces in everything has always been strong, starting from the myriad of anthropomorphizations in animist cultures where every thing has its soul, and it keeps making us seeing ghosts in machines, leading to what one may call the “pareidolia fallacy”: we see agency where there is none.
Agency and creativity require Daniel Dennetts intentional stance and teleology, the ability to direct actions toward goals emerging from imagined interactions with an internal model of the world, to evaluate outcomes in relation to one’s own aims. This is a cognitive feature not only observable in humans, but (at least) in all mammals: Watch a squirrel on a tree trying to figure out if it can jump to the next. It looks at the tree, its head moves up and down, it evaluates distance and its own abilities. It goes like that for a while, and then it decides if it can do it, and takes the jump. That’s precisely the “imagined interaction with an internal model of the world, to evaluate outcomes in relation to one’s own aims”. AI has none of that.
While AI models do show a synthetic theory of mind, where they build representation of its users during conversation, these work very differently from those of humans, and compared to them, they don’t work well. Chatbots have no intrinsic motivation, no sense of why it “speaks”, and no capacity to care about the coherence of its outputs beyond statistical continuity. All true and meaningful selection occurs externally, through human feedback and usage.
In LLMs, the pareidolia fallacy makes us asume cognition, creativity, and agency where there’s computational interpolation of language patterns in the giant wobbly archive of a new kind. What differentiates these new interpolatable archives from previous archives is obvious: They interpolate their contents. Where classic archives provide access to fixed records of text, video, audio and artifacts of human culture, this new archival access has atomized its contents, and only provides interpolated amalgams, chimeras and fusions. Depending on your stance about the definition of “archive” you might object to my interpretation at this point, and i’d nod and say “That’s what’s new”.
Digital Oralities
In “Large Language Models As The Tales That Are Sung”, Henry Farrell describes LLMs as structural similar to oral traditions and folklore: “LLMs are not the singer, despite their apparent responsiveness, but the structural relations of the tales that are sung”, reminding me of the pre-homeric rhapsodes, the bardes who sang the old stories of “The Iliad“ and “The Odyssey” long before Homer sat down and put them in writing. They did so by using preconfigured language modules with which they constructed their poems while they were sung, a “grammar” of mnemonic formulas and repetitions to solve the problem of creating narrative in real-time. These are the oral precursors for the optimized, averaged language codes we loathe so much when they come from AI.
Interpolatable Archives work similar, like a statistical mnemosyne (the godess of memory in greek mythology) speaking in tongues, giving probabilistic answers to specific inquiries. Knowledge transfer through those new oracles means a shift from traditional “archival epistemologies”, where knowledge is grounded in traceable facts and specific, identifyable sources, to a fuzzy oracular epistemology where responses are generated on-demand by an opaque interface, turning inquiry into digital hyper-orality.
Where oral traditions of yore served as mnemonic technologies integrated into the communal structures of everyday life, this digital hyper-orality is different. The entirety of human thought —well, as for now: The entirety of human thought on the internet, which… sigh…— becomes epistemic stockpile, a resource to be mined, refined, and dispensed on demand, stripped of its being-in-the-world.
Without being grounded in life, AI dissolves the episteme, the based knowledge including citations, sources and authorial intent, and make place for a 128kbps MP3 of the “tales that are sung”. The value of such information lies within its statistical probability and the stylistic resonance in the reader, rather than its referential grounding in reality. It speaks to us, or it doesn’t: finding meaning in stochastic output is entirely to the user. Social Media already innitiated this crisis of the episteme and the emergence of new oralities through phenomena like context collapse. On platforms, vibes-based knowledge reigns supreme. LLMs further accelerate it.
This sounds as bad as it can be, and I won’t downplay the risk here, but I want to draw your attention back to Aby Warburg at this point. His project of the Mnemosyne Atlas, that “associative image-based map of meaning”, was an attempt at tracing the recurrence of symbolic representation throughout visual history in a non-linear archive. Warburgs’ library, while still providing based epistemic grounding to its records, was introducing a second layer that intentionally dissolved the episteme with idiosyncratic indexing, allowing for access by free association, working similar to those new interpolatable archives.
LLMs generate not fixed images or texts, but interpolations across associative symbolic fields, enabling a new kind of navigation of a vast symbolic space of possibilities. The dissolution of the episteme in digital oralities, like Warburgs’ associative Bilderatlas, then can be read not only as a risk, but a liberation aswell, and a cognitive catalyst.
Ernst Cassierer took inspiration for his groundbreaking philosophy of the human as the "symbolic animal" from Warburgs' institute and his associative archive.
Borges hints at how he landed on 22 letters of the alphabet, instead of the 26 of the standard latin, or the 30 of the spanish alphabet, in his initial essay about “The Total Library” (PDF), about which Jonathan Basile, creator of the Library of Babel on the web, writes: “Presumably Borges is starting from the 30-letter modern Spanish alphabet, and rejecting the double letters (ch, ll, rr) as unnecessary along with the ñ. The remaining 26 include k and w, which appear only in loan words. Borges then removes q as ‘completely superfluous’ (debatable) and x as merely ‘an abbreviation’.”
Writing about LLMs in the afterword for the 2022 english edition “What If?” of Villem Flussers “Angenommen. Eine Szenenfolge.”, Kenny Goldsmiths shows himself quite bored of the averaged poetry generated by AI and “wants to see artificial intelligence bent and twisted in ways to show us truly new forms of language”, asking “Can AI be ‘queered’? Could AI be trained to be intentionally perverse, something notoriously difficult to define, let alone program? (…) Could AI be trained to intentionally get it exactly wrong?” The inherent hallucinative qualities of the interpolatable archives may soon make place for boring guardrailed correctness, but for those of us who enjoy the glitch and error for artful purposes, this is a refreshing take on LLMs in times of a critique that insists on a purity of the factual. On a more technical level, to me, the true signs of intelligence in an AI-system would be its ability to produce errors and hallucinations on purpose, or to understand and generate paradoxa which make sense as a metaphor. For now, these irrational markers of true cognition seem to be reserved for the human.
These prisms are more than a metaphor and have been produced in optical neural networks. They are not shapeshifting, ofcourse, but you can shine lights through it and they identify images of handwritten digits.
If LLMs are or are not lossy compressions of their training data is subject of debate since their inception. While some explain the fact that LLMs do memorize their training data with overfitting, others claim that those vibes encoded in LLMs are so finegrained they are simply the same as lossy compressions. Here’s one of the latest papers from April 2026 making that claim, and here’s a nontechnical summary. I come down on the compression side of the argument, but i think my description of AI-systems as interpolatable archives works both ways.